AncientDoc,这个号称“首个中国古代文献理解系统基准”,顶着某知名大厂和某Top3高校的双重光环,居然是一个错漏百出、粗制滥造的半成品,如此荒诞无稽的事情,是对学术底线的无情嘲笑,是对狂飙突进的当头棒喝,将当前AI领域充斥的狂热、浮躁的底色暴露无遗。下面就由我来逐步拆解其华而不实、徒有其表的真相。
话说几天前,一位同事分享给我一篇介绍AncientDoc的文章,名为《首个中国古代文献理解系统基准 AncientDoc发布,复旦与字节共护文化瑰宝》。发表时间在2025年9月左右,在微信公众号、知乎、小红书等平台都很容易找到。
用他们自己的话来说,AncientDoc作为一个“面向中国古籍的多任务视觉语言模型评测基准”,“涵盖页面级OCR识别、文言到白话翻译、因果/立意类推理问答、历史知识类问答、以及风格识别与语言变体问答”等五个领域。
最近半年多来,大模型OCR特别火热,我也在使用多个大模型处理现代图书文献的OCR任务。但是所有这些模型在古籍文献方面的表现都远远不及预期。因此,我特别关注了“页面级OCR识别”的评测结果。
第一个令人费解之处:即便是表现最佳的Gemini2.5-Pro,CER(字符错误率)也竟然高达32.03%,F1只有18.12%。为了解释这个如此离谱的结果,我虚心向ChatGPT请教,同为大模型的它用洋洋洒洒的一篇雄文竭力为其挽尊:
从纯数学角度说,确实意味着平均每 100 个字符有 32 个发生编辑错误。但 ⚠️ 前提是:模型输出和 GT 是“同一字符序列空间中的逐字对齐结果”。
经过三个大段分析论证,最后ChatGPT还是不得不老老实实的承认:
如果你问:“这些模型能不能把古籍内容读出来?”
答案是:能,而且语义层面可能远好于 CER 所暗示的水平。
如果你问:“这些模型能不能作为古籍数字化 OCR 引擎?”
答案是:目前基本不能。
为了验证这桩“32.03%”的疑案,同时也是为狠狠打脸这些自以为是的大模型,我决定用古籍酷OCR进行独立验证。
首先是下载数据集。命令行如下:
hf download yuchuan123/AncientDoc --local-dir ./AncientDoc --repo-type dataset
(本地Python环境需要提前安装huggingface-hub)数据集分14个大类,含135本古籍,2980张图片。标注文件label.csv,包含2584条数据,“OCR”数据列含2580条有效数据。
然后我调用本地部署的古籍酷ocr_pro API,得到2979个有效识别结果(排除空白页1张),与标注数据匹配后,得到2580个文本对。
由于标注文件中的换行符号不统一,存在无换行、“\n”,“\\n”等三种情况,为公平和严谨起见,将标注文件和古籍酷OCR结果的换行符号全部删除。同时标注文件中未对双行夹注进行标记,故而将古籍酷OCR结果中的双行夹注标记也尽数删除。CER的计算公式如下:
CER=(S+D+I)/N
S:替换(Substitution)
D:删除(Deletion)
I:插入(Insertion)
N:参考文本字符数
编辑次数计算使用Levenshtein库中的editop函数。简化后的核心评价函数大致如下:
from Levenshtein import editop
def evaluate_ocr(gt_texts:list[str], pred_texts:list[str]):
total_S = total_D = total_I = total_N = 0
for gt, pred in zip(gt_texts, pred_texts):
total_N += len(gt)
S = D = I = 0
ops = editops(gt, pred)
for op, i, j in ops:
if op == "replace":
S += 1
elif op == "delete":
D += 1
elif op == "insert":
I += 1
total_S += S
total_D += D
total_I += I
CER = (total_S + total_D + total_I) / total_N * 100
第二个费解之处出现了,古籍酷OCR的CER居然也有33.99%。这完全不可理喻。由此我将调查矛头从大模型指向评测本身。调查结果令人震惊,33.99%与其说是古籍酷OCR,倒不如说评测集本身的CER!这里举几个简单的例子来说明这个评测集有多么离谱、多么儿戏!

不足100字,最简单的一页古籍,给出的基准文本居然让人完全读不懂,文本顺序颠倒错乱,左右横跳,上下乱飞,甚至出现了阿拉伯数字:
弩牌鎗砲銃鑑笵甲清水泉清竹木清硝磺鉛鐵清什物安鄉氏一事權和衆志編丁壯弩箭刀筅棒鎗甲弩牌鑑銃笵清五穀清芻草清野第⑤清屋宇清油蠟清地面筹方略第⑥分信地擇賢能汎守具
相比之下,古籍酷的结果完全正确,并且有分行,而CER是101%。这难道不应该是基准文本的CER吗?
弩 弩箭\n牌 刀\n鎗 筅\n鈀 棒\n盔 鎧甲\n籌清野第五\n清五榖 清水泉\n清芻草 清竹木\n清屋宇 清硝磺鉛鐵\n清油蠟 清什物\n清地面\n籌方略第六\n安郷民 詰奸細\n一事權 分信地\n和衆志 擇賢能\n編丁壮 𣲖守具\n總目 四

第二个示例。其基准文本原本是不含换行的。为了便于阅读,暂且加上换行,并在括号中注明明显的遗漏,错字则不再一一注明。
選梓天鏡卷之一下 (缺两行) 論歲月 太歲為一年萬神之主宰戊巳都天為一年吉凶神煞之 統領歲破三煞金神天地官符等為一年輪占山向之凶 神造塋修方往來抵向或擇用日辰犯之災禍極速蓋諸 凶煞係太歲干支為主故凡用事亦取年命干支以避之 至選用吉神乃每年逐月遇天月德二德合歲德金玉 堂天嗣天恩太陽天喜等直日當以本命日辰取用或為 我命貴祿馬或生助比和不落旬空而又無刑沖剋害此 真上吉期也 凡年月凶煞在山在向皆以定位為重若以月建飛到山 向為遇吉曜可解(缺十五字) 坤八震九巽逆飛一中二巽三震四坤五坎六離七艮八 兌九乾遇而復始 天月二德乃年中至吉之神所到之處大能扶助吉神解 除凶煞法以月建入中宮順飛九位如戊辰年三月修坤 方天月二德在壬以丙辰建入中宮尋見壬戌泊坤為天 月二德到也又看值日真德如三月丁亥日系甲申旬中 以丙辰入中宮尋見壬辰泊中宮為真德到也餘倣此 論日 日干為主日支為佐與月令同氣或與月三合或月建相 生及歲德天月德為上吉三德合日恩天赦日次吉 日貴旺相得令忌休囚無氣而日干尤重日之吉凶全看
跟古籍酷OCR的识别结果对照后,CER为24.87%。即便是这么简单的版式,基准文本也存在相当多的漏字,显然是没有经过严谨校对,这与那篇文章所号称的内容完全是南辕北辙、大相径庭。现在读起来,十分讽刺:
“精确还原一整页文本的内容。”
“针对OCR 输出中的排版顺序、断句混乱、注释混淆等问题,逐一进行重排与标点修正;”
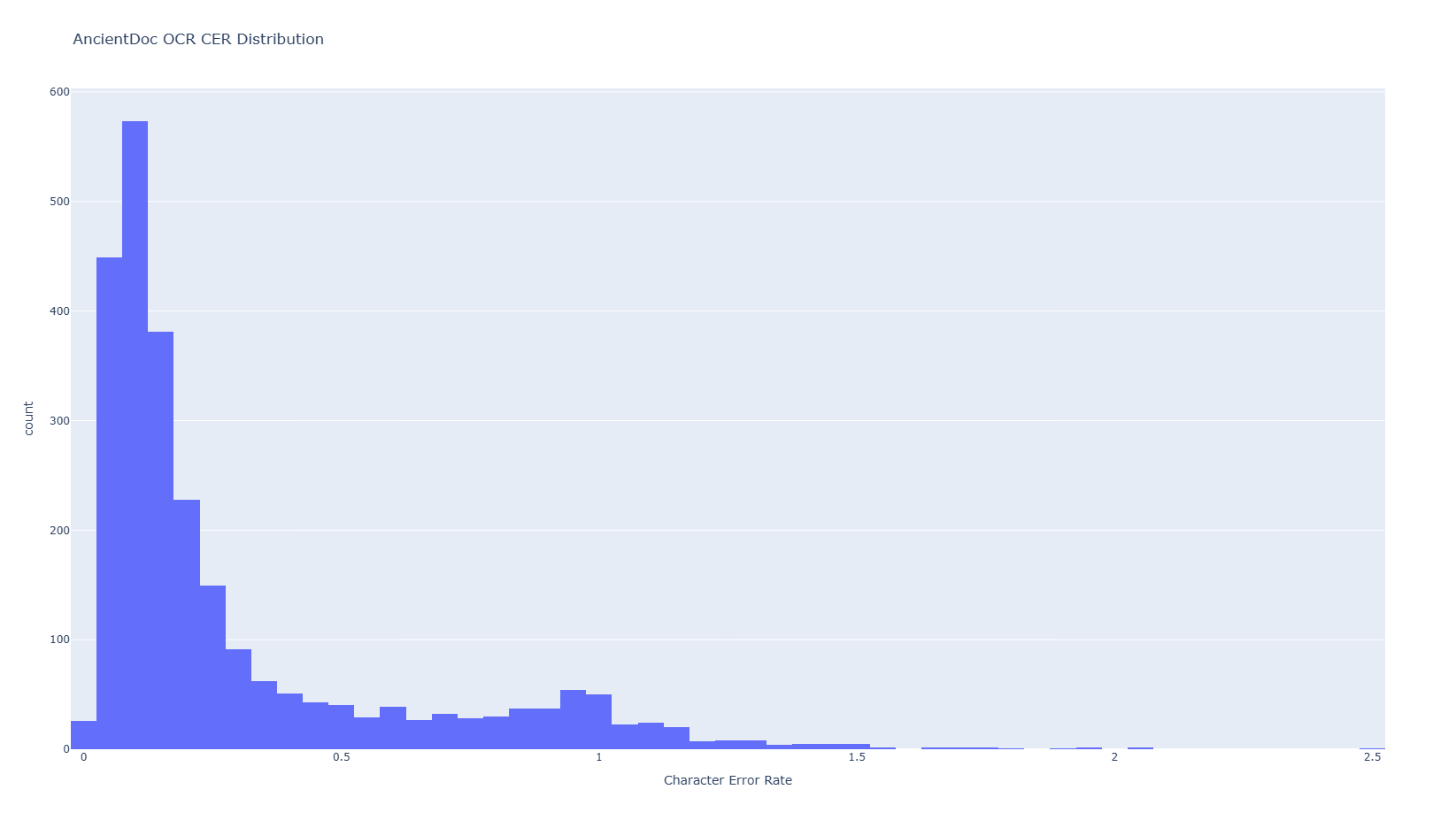
这些根本不是孤例,我针对所有样本做了直方图统计,使用的是plotly.express库的histogram函数。从中发现整个评测集存在相当比例的高CER样本,甚至在100%处形成了一个峰值。
为了更加全面直观的展示评测集的样本特征,我使用plotly.express库的bar、box函数绘制了书籍大类的平均CER条形图和各书籍CER的线箱图。
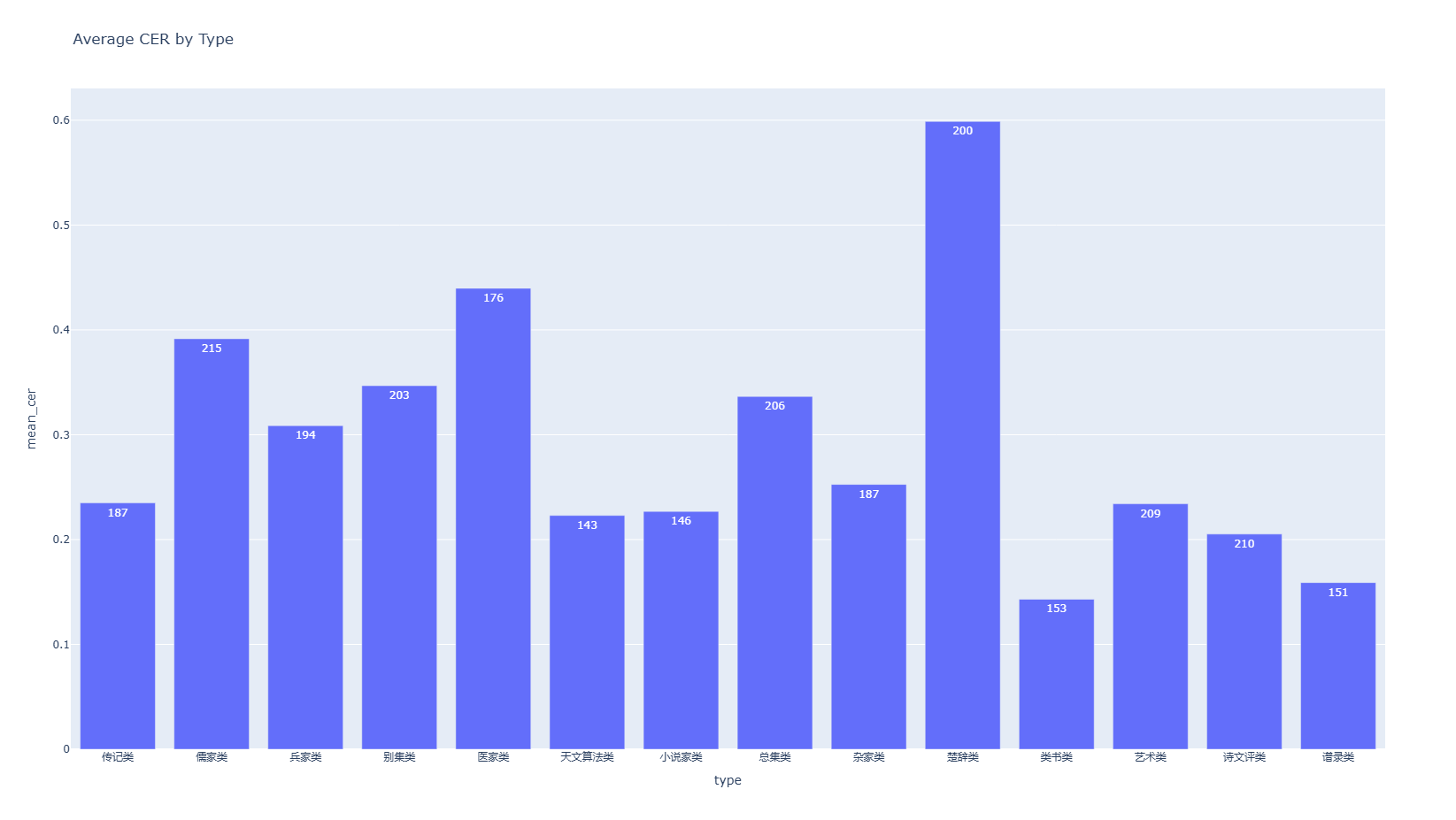
从书籍类别来看,楚辞类的平均CER高达60%,而楚辞类的三部书籍(《楚辞集注》、《楚辞新注》、《楚辞朱注》)全部是注疏体,存在大量双行夹注。
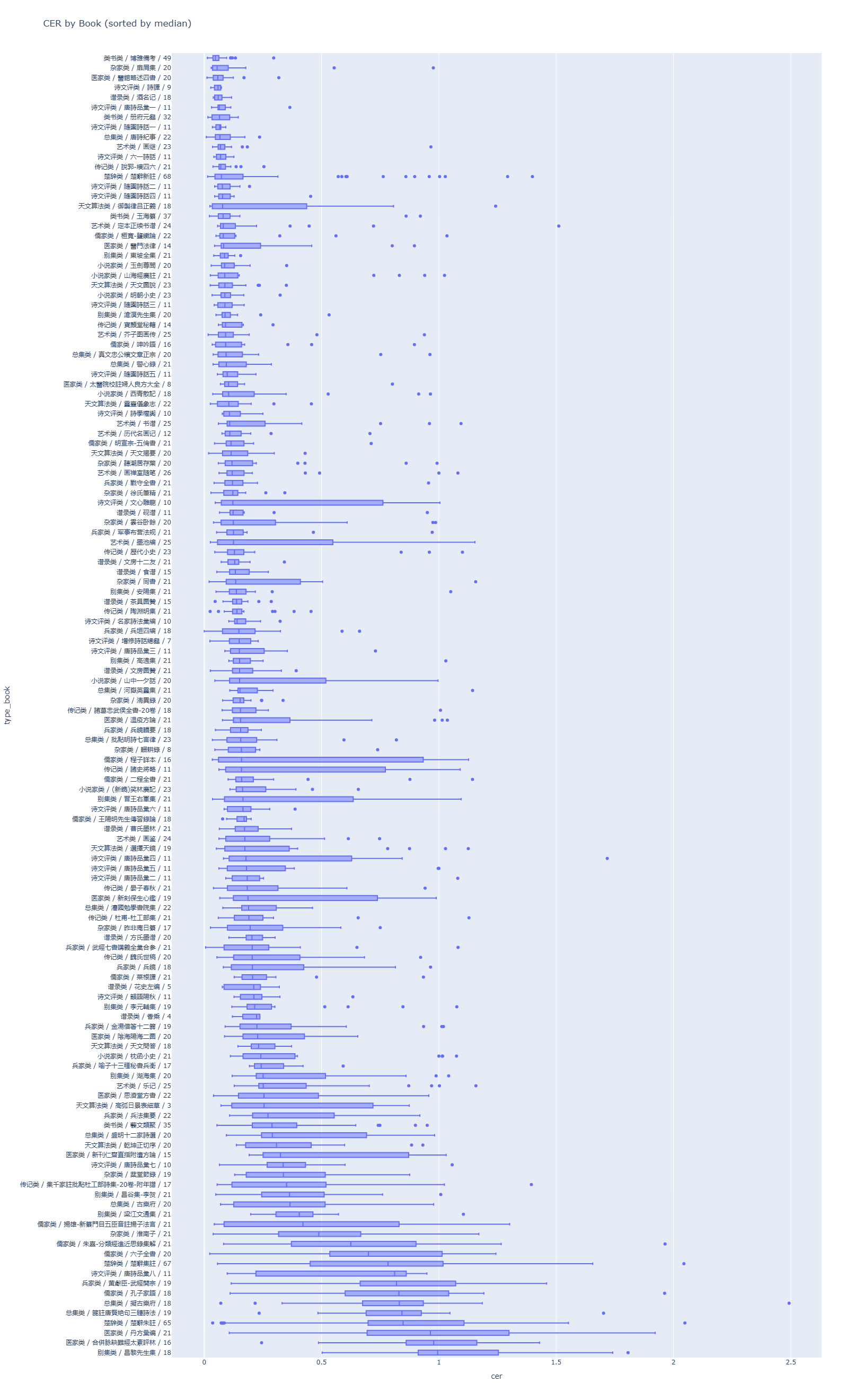
CER中位数接近100%的几本书,比如别集类的《昌黎先生集》,医家类的《合併脉訣難經太素評林》、《丹方彚编》,无一例外的,绝大多数页面都是含有双行夹注的。
测试几家平台(主要是古联、开源的paddle、小红书的dots.ocr)以后,还是感觉处理一个宋本双行小字的识别准确率比较低。这个版本的双行小字笔画太细,测试下来,转黑白后对ocr识别影响较大。古籍酷能很好地处理这个场景吗?
又特地发了两页图片样本,给我测试。

在我看来,这只是比较普通的双行夹注场景,使用古籍酷API,即便不做任何图像预处理,理论上也不存在任何难度。于是我建议他去古籍酷的“API演示”网页自行测试即可,无需登录。
事后我也自行测了一下,不出所料,识别结果相当完美。即便遇到个别黑底白字的情况,也能精准识别。

回过头看来,AncientDoc的天大笑话,既有方法论上的缺陷,也有对古籍文献傲慢的成分。
在方法论上,他们采用了“模型预标注+人工精修”的两阶段模式。预标注采用的模型是Qwen2.5-VL-72B。这个模型本身在古籍OCR任务上的效果就很差。在最终评测环节,该模型的CER是夸张的58.83%。而评测集的总字数是763219,相当于他们在人工精修环节进行了44.9万次的编辑。从好的方面说,他们确实尽力了。不过从古籍酷的交叉验证来看,评测集的实际错误率极大可能还在33.99%上下。这意味着:为了达到完美的结果,他们大概还要再进行25.9万次编辑,整体的编辑次数将高达总字数的93%(58.83%+33.99%),这难道跟全部人工录入有什么区别吗?
这里我衷心奉劝他们,如果AncientDoc还有2.0版的话,那么与其继续屎上雕花,不如推倒重来,直接替换成古籍酷OCR的识别结果,然后对我们的热心帮助致以诚挚的感谢,最好能再从我们这儿学到一点儿真正的学术态度和工匠精神,也不枉一个大厂再加上一个TOP3的雅量。
特此说明:以上全部打字手写,无任何AI改写精修。