笔者从研究生期间开始关注清代民国北京话文献的发掘整理工作,涉及满汉合璧文献、小说、戏曲、域外教科书、白话报等多种题材,一直在跟古籍、老报纸和各种OCR软件打交道。因为汉语史研究离不开语料库,新文献只有数字化才能更好地服务学界,如何将海量的新发掘文献进行录入标点就成为一个难题。
从早期五花八门的单机版OCR软件,到近年来兴起的AI+OCR路线,笔者见证了技术进步给古籍整理工作带来的便利,多次试错之后也有一个体会:如果录入标点的正确率不是非常高、版式识别不是足够精准,如果AI在提升了正确率的同时加入一些联想的内容,那么校对所需的人力和资金投入可能比直接找录入公司更高。
2022年,《早期北京话珍本典籍校释与研究续编》入选《“十四五”时期国家重点图书、音像、电子出版物出版专项规划》,笔者负责其中《早期北京珍稀文献集成续编》(47卷本)的统筹工作,130余种全新文献必须在2026年完成整理出版工作。次年,笔者申报的社科基金《白话报刊多层标注语料库建设与研究》立项。两项工作虽前期已有一定积累,但任务仍十分繁重,尤其是民国白话报刊,动辄就是上亿、十亿字的规模,课题经费完全是杯水车薪,必须另辟蹊径。
后来经从事中文信息处理研究的朋友推荐,笔者试用了古籍酷平台,并幸运入选了“数字万舟”项目首批资助计划。古籍酷平台提供的公益OCR额度对笔者的整理研究工作起到了很大的帮助,《早期北京话珍本典籍校释与研究续编》丛书进展顺利,获得2024年国家出版基金资助,各分卷已由北京大学出版社陆续推出。

笔者牵头建设的早期北京话公益语料库项目上线后得到了同行的肯定,并在今年获得中国教育技术协会“数字教育创新成果奖”二等奖,白话报刊语料库也在有条不紊的推进之中。
在古籍酷平台的实际使用过程中,我觉得下面几个特性最为受用:
(一)文字识别的正确率高,校对方便

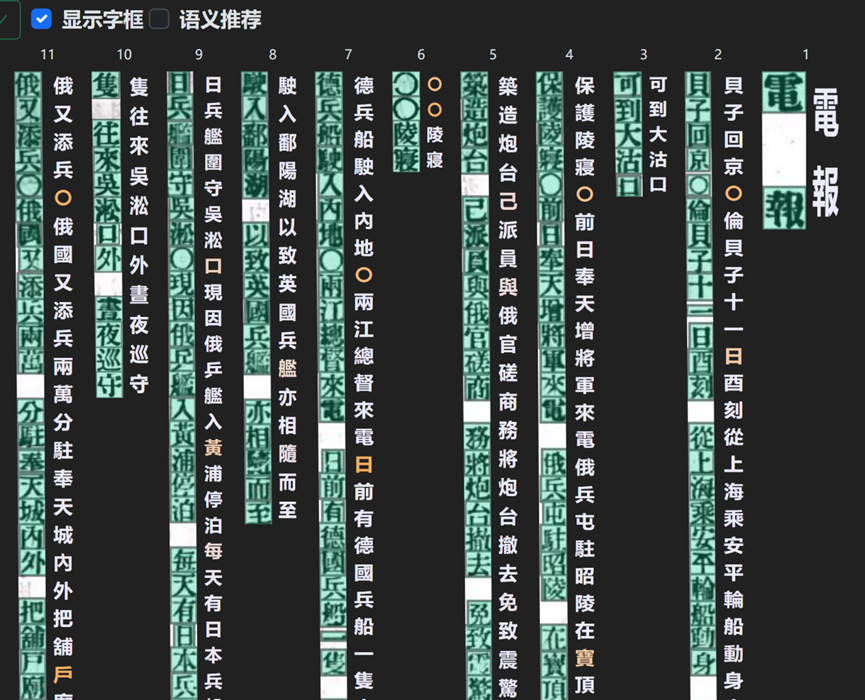
左页的白话报只有一处○识别有误,其他文字都识别正确,其古籍OCR正确率始终居于国内外同类产品的第一梯队。
在点击界面的图文对照图表后,提供了原文和OCR结果的平行对照,黄色字体提示了可能会识别错误的字,可以及时修改和自动标点,大大提高了校对效率。
(二)标点正确率高
经笔者初步测试,目前不管是文言、文白夹杂,还是白话文,古籍酷标点的正确率都很高,毫不逊色于国内主流大语言模型,明显优于一些开源的中文标点模型和免费标点的平台。
以1942年两段报刊新闻为例:
测试一:
1、古籍酷:
同时据柏林消息:一、大队红军正在都普斯及斯达林格勒两区与陆军联络作战;二、阿斯特拉汉克拉斯尼军品特公路阻断后,敌军前后方交通大受影响。
2.国内知名大语言模型:
同时,据柏林消息,一大队红军正在都普斯及斯达林格勒两区与陆军联络作战。二、阿斯特拉汉克拉斯尼军品特公路阻断后,敌军前后方交通大受影响。
3.国外知名大语言模型:
同时,据柏林消息,一大队红军正在都普斯及斯达林格勒两区与陆军联络作战。二阿斯特拉汉、克拉斯尼军品特公路阻断后,敌军前后方交通大受影响。
4.口碑较好的开源标点模型:
同时据柏林消息,一;大队红军,正在都普斯及斯达林格勒两区,与陆军联络作战二;阿斯特拉汉克拉斯尼军品特公路阻断后敌军前后方交通,大受影响。
5.国内免费的标点平台:
同时据柏林消息,一、大队红军正在都,普斯及斯达林格勒两区与陆军联络。作;战。二、阿斯特拉汉克拉斯尼军品特公路阻断,后敌军前后方交通,大受影响。
测试二:
1、古籍酷:
19420002352026柏林三十一日同盟社电:苏联在东线集中军队与军火,以备冬季大举反攻,藉驱德人于占领区以外。柏林政界对于此举,谓德国亦有准备,现下德军已完全控制斯达林格勒及其余各地,红军虽汇集于前线一带,德国军官决不予以可乘之隙也。
2、国内知名大语言模型:
1942年(注:原文“19420002352026”可能为电报代码或日期错误,根据上下文推断为1942年),柏林三十一日同盟社电:苏联在东线集中军队与军火,以备冬季大举反攻,藉驱德人于占领区以外。柏林政界对于此举谓德国亦有准备。现下德军已完全控制斯达林格勒及其余各地。红军虽汇集于前线一带,德国军官决不予以可乘之隙也。
3、国外知名大语言模型:
1942年12月31日,柏林三十一日,同盟社电:苏联在东线集中军队与军火,以备冬季大举反攻,藉驱德人于占领区以外。柏林政界对于此举谓德国亦有准备。现下,德军已完全控制斯达林格勒及其余各地,红军虽汇集于前线一带,德国军官决不予以可乘之隙也。
第二个测试中,两个大语言模型都把录入序号进行了错误推理和修改。这也是笔者最近试用一些AI+OCR产品时遇到的共性问题。利用大语言模型和上下文语义计算疑难字和标点的出现概率是趋势,一些肉眼无法识别的字,ai有时能猜对,有时不仅猜不对还会瞎编内容,古籍酷技术团队不仅紧跟潮流,还能扬长避短,实属难得。
(三)沟通顺畅,更新及时
使用中的一些问题和需求在微信群中都能够得到张敬经理和工程师的及时反馈,平台也能够不断根据客户需求进行更新,如近期就上线了科判、聚类校对、批量处理和API额度共享等新功能。
古籍酷平台不仅在“数字万舟”项目中为研究者和机构提供价值不菲的文字识别和标点额度,每天给注册用户提供的免费额度也足以支撑多数研究之需,这份公心,令人钦佩。作为切实的受益者之一,我衷心希望古籍酷平台能够越办越好,普惠学林。
作者系对外经济贸易大学北京语言与文化研究中心主任、教授,国家社科基金重大项目“白话报刊多层标注语料库建设与研究(1815-1949)”首席专家。