历经半年多的准备,新版古籍OCR终于上线。相比之前的版本,新版在若干方面取得了巨大提升。
首先,最明显的是识别准确率,尤其是在生僻字方面。在严格异体字认同的条件下,准确率仍然到达99.1%的水平。以下面的敦煌写经为例,识别结果中属于CJK扩展区的生僻字形多达14种:


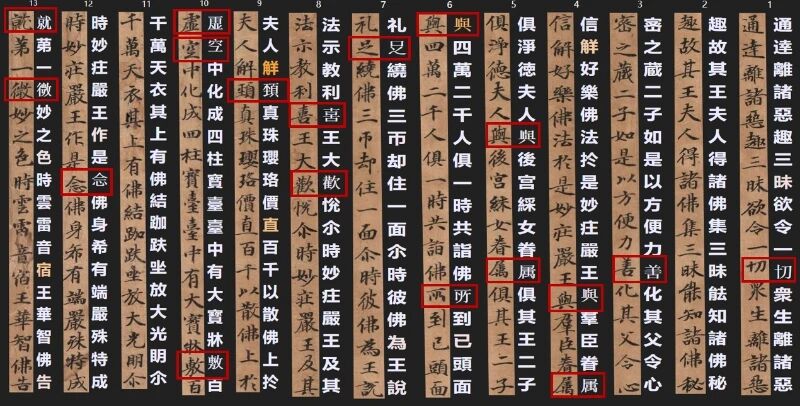
第二,字数密集的情况下识别效果也获得显著提升。例如,以下图片中的1600余汉字几乎全部被完整检测出来,并且处理时间从之前长达数十秒缩短至10秒以内。

第三是识别速度。得益于新架构的算法优化,在本地部署环境中,单卡日处理量超过12万页,相当于之前的三倍。
为了提高使用便利性,新版服务的 API 和网页批量的权限进行了合并,授权用户可同时使用 API 调用和网页端批量,不必分别申请,额度通用。新版服务还对API调用参数进行了简化,以适应新版OCR的特点。
需要注意的是,在新旧服务切换期间,两者的使用额度相互独立,已授权用户可以申请将未使用完的额度转移至新版服务,费用标准暂时不变。但是原网页批量处理的数据不会转移至新服务,需要用户自行下载保存,切换服务后原数据将无法访问。